
Intro
After upgrading from Node 20 to 24, I noticed something unexpected in our monitoring dashboards: CPU usage dropped, event loop delay got smoother, and GC pauses shortened, all without changing any application code.
The deploy finished on Thursday at 11:00 AM. The dashed red line is last week's trend (Node 20), the solid blue line is this week (Node 24):
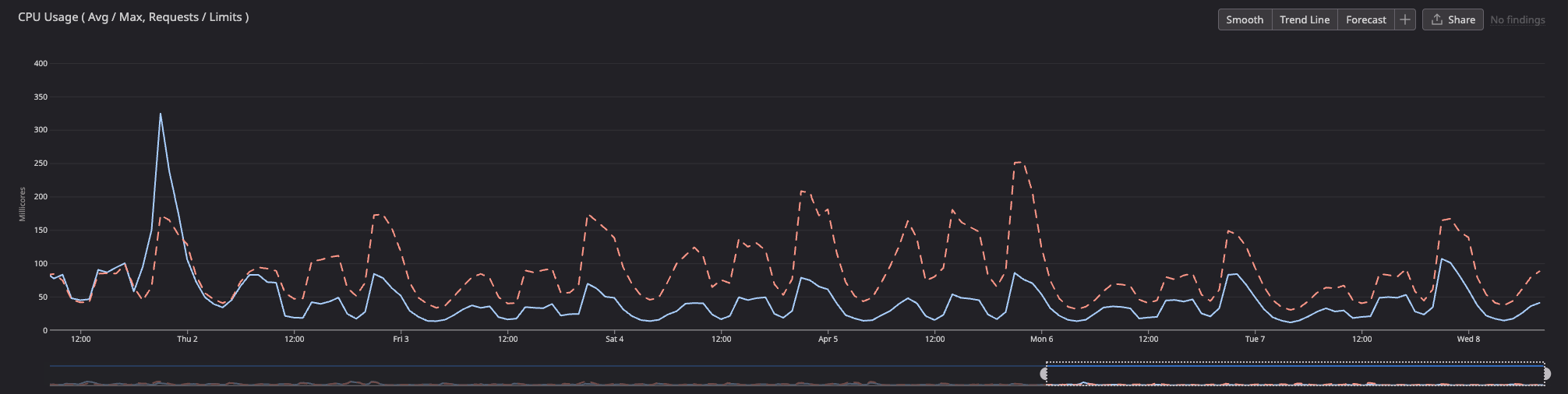
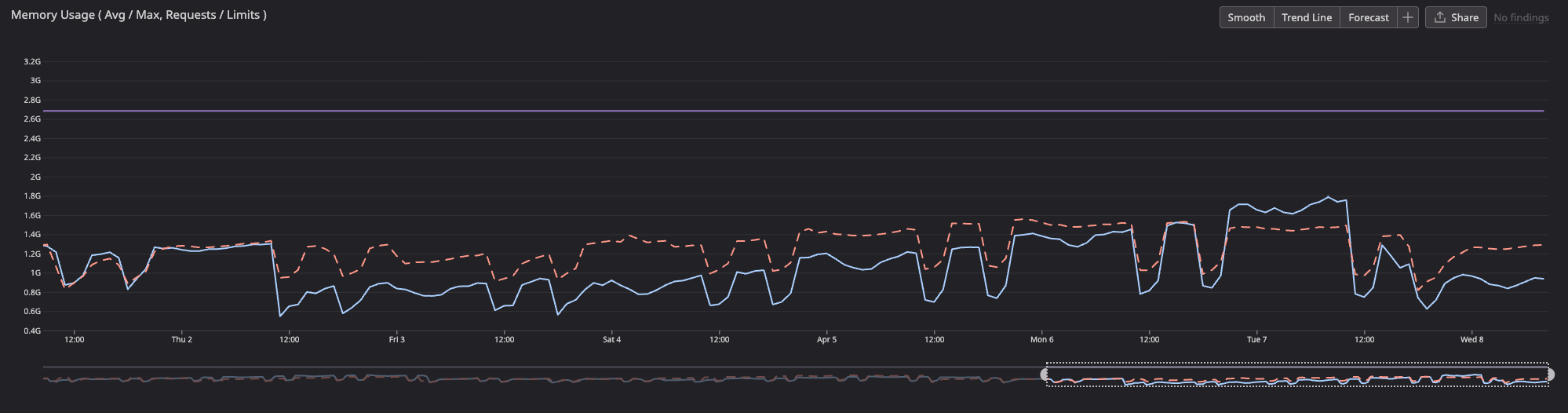
I wanted to understand why, so I dug into what changed between Node 20 and 24 under the hood.
Turns out, it's not one thing. It's several compounding improvements across V8 engine upgrades, a new JIT compiler, GC heuristic changes, and core API optimizations, all landing at once when you jump 4 major versions.
1. V8 Engine: 11.3 → 13.6
Node 20 shipped with V8 11.3. Node 24 runs V8 13.6. That's a massive jump. Every intermediate Node version (21, 22, 23) brought its own V8 upgrade, each with better JIT compilation, smarter inlining, reduced bytecode overhead, and improved object shape tracking.
V8 optimizes JavaScript execution through just-in-time (JIT) compilation and efficient memory management. The cumulative effect of going from 11.3 to 13.6 in one shot is significant.
2. The Maglev JIT Compiler
This is arguably the single biggest factor.
Maglev is V8's new mid-tier JIT compiler, introduced in Node 22 and mature by Node 24. It sits between Sparkplug and TurboFan in the compilation pipeline:
| Compiler | Compile speed | Code quality |
|---|---|---|
| Sparkplug | Fast | Basic |
| Maglev | Medium | Good |
| TurboFan | Slow | Optimal |
Before Maglev, V8 had a gap. Sparkplug compiled fast but produced mediocre code, and TurboFan produced great code but took a while to kick in. Functions that ran often enough to matter but not enough to trigger TurboFan were stuck with Sparkplug's output.
Maglev fills that gap. It compiles faster than TurboFan but generates significantly better code than Sparkplug, making it especially beneficial for short-lived functions and server-side rendering. It also uses less off-thread CPU time, which directly explains the CPU usage drop.
Note: Maglev was briefly disabled in Node v22.9.0 due to stability concerns, but was re-enabled and stabilized for Node 24.
3. Streams API Optimizations (Node 21+)
Next.js does a lot of streaming (SSR, API routes, React Server Components). Starting in Node 21, the Streams API underwent optimizations achieving approximately a 10% speedup by:
- Eliminating redundant checks
- Utilizing bitmaps for state tracking
- Scheduling callbacks more efficiently
Additionally, chunked response writes were consolidated to avoid creating a separate chunk per .write() call, reducing overhead on both the server and client side. For an SSR-heavy Next.js app, this adds up.
4. AbortSignal Performance (Node 22)
Node 22 enhanced the efficiency of creating AbortSignal instances, leading to significantly improved performance in fetch and other APIs that rely on them.
If your Next.js app uses fetch heavily (data fetching in RSCs, API route handlers, middleware), this directly improves event loop throughput. Fewer cycles spent constructing and managing abort signals means more cycles for actual work.
5. Undici 7.0 HTTP Client (Node 24)
Node 24 upgrades the built-in Undici HTTP client to version 7.0, improving spec compliance and smoothing out the developer experience when using fetch(). Faster, more predictable HTTP handling means less time blocked on I/O callbacks in the event loop.
6. GC Pause Improvements
GC pause times on sustained load dropped from an average of ~12ms in Node 22 down to ~8ms in Node 24, roughly a 33% reduction. Fewer and shorter GC pauses means fewer event loop stalls, which shows up directly as reduced event loop delay in your metrics.
On heap_size_limit Increasing
One thing I noticed: heap_size_limit went up after the upgrade. At first this seemed concerning. Is the app leaking memory?
No. It's actually a good sign.
Newer V8 versions (around Node 22+) incorporate heuristics that set the default New Space size dynamically based on available system memory, rather than using static defaults. V8 is now giving itself a larger ceiling to work with.
The key insight: a larger buffer for newly allocated objects gives the rapid Scavenge collector more time to identify and reclaim short-lived garbage before the allocation space fills up. This significantly reduces premature promotion to Old Space, which in turn reduces the frequency of slow, disruptive Old Space (major) GC cycles.
In other words: higher heap_size_limit → fewer major GC cycles → less CPU usage and lower event loop delays. The runtime is trading a bit of memory headroom for dramatically less GC pressure.
In most production environments, RAM is more abundant than CPU cycles, so allocating more memory to reduce GC overhead is a sound trade-off.
Why Average Event Loop Delay Went Up Slightly
Here's a counterintuitive one: after the upgrade, the max event loop delay dropped dramatically, but the average/median nudged up slightly. Is that bad?
No. It's actually the expected pattern with these improvements.
Before (Node 20): The event loop was occasionally getting hammered by GC pauses or unoptimized JIT code, spiking the max to very high values. Between those spikes, things might idle very low, pulling the average down artificially.
After (Node 24): The runtime works more consistently. Maglev is actively JIT-compiling more code more of the time, GC runs more frequently but in smaller increments rather than big stop-the-world pauses. The average reflects a busier-but-healthier baseline, while the catastrophic spikes are gone.
Think of it like this:
- Before: mostly 2ms, then occasional 200ms spikes → low average, high max
- After: consistently 5ms, no spikes → slightly higher average, much lower max
From a user experience perspective, max and p99 are what actually matter. A lower max means your worst-case request latency improved. A slightly higher average in a flat, spike-free distribution is far preferable to a low average with unpredictable large spikes.
Less variance, lower ceiling. That's the goal.
Summary
| Change | Node version | Impact |
|---|---|---|
| V8 11.3 → 13.6 | 21 → 24 | Faster JIT, better optimization |
| Maglev JIT compiler | 22/24 | Lower CPU, less off-thread overhead |
| Streams ~10% speedup | 21+ | Lower event loop load for SSR |
| AbortSignal perf | 22 | Faster fetch / RSC data fetching |
| Undici 7.0 | 24 | Better HTTP throughput |
| Smarter GC heuristics | 22+ | Fewer GC pauses, trades RAM for CPU |
Higher heap_size_limit | 22+ | Side effect of smarter GC, a good thing |
You're essentially getting 4 years of V8 and Node.js runtime improvements in one shot. Next.js, with its heavy use of streams, fetch, and SSR, benefits from almost all of them.

